Welcome to the world of Databricks! This powerful cloud-based data platform is designed to help organizations optimize their workflows and streamline their data engineering processes. In this deep dive, we will explore the many features and capabilities of Databricks that make it an essential tool for any data engineer.
Toc
Introduction of Databricks
![]()
In today’s rapidly evolving data landscape, data engineering has become more critical than ever. The ability to efficiently manage and process large volumes of data is essential for businesses to stay competitive. Databricks, a unified data analytics platform, has emerged as a game-changer for data engineers. This article explores the significance of Databricks in the data engineering landscape and provides a comprehensive guide on leveraging its features for optimal results.
What is Databricks?
Databricks is a unified analytics platform that combines data engineering, machine learning, and business intelligence in one collaborative workspace. It was created by the original creators of Apache Spark, making it a highly efficient and scalable solution for big data processing. It is built on top of Apache Spark, providing a unified interface for data engineers to manage their data pipelines and perform complex transformations seamlessly.
Key Features of Databricks
Databricks offers a wide range of features that make it an indispensable tool for data engineers. Let’s take a look at some of its key features:
- Unified Workspace: Databricks provides a centralized workspace where data engineers can collaborate, build, and deploy data pipelines with ease.
- Auto-Scaling Cluster: With Databricks, users don’t have to worry about configuring clusters manually. The platform automatically scales up or down based on the workload, ensuring optimal resource utilization.
- Seamless Integration: Databricks seamlessly integrates with various data sources, including SQL databases, NoSQL databases, and cloud storage services like Amazon S3 and Azure Blob Storage.
- Advanced Analytics: The platform offers built-in support for machine learning and advanced analytics capabilities, allowing data engineers to build predictive models and perform complex data analysis tasks easily.
Benefits of Using Databricks
Databricks offers numerous benefits that make it a popular choice among data engineers. Some of these include:
- Scalability: As mentioned earlier, Databricks uses Apache Spark as its core processing engine, making it highly scalable and capable of handling massive volumes of data.
- Reduced Maintenance: Databricks takes care of many administrative tasks, such as cluster management and job scheduling, reducing the burden on data engineers and allowing them to focus on more critical tasks.
- Cost-Effective: The auto-scaling feature in Databricks ensures optimal resource utilization, leading to cost savings for organizations.
- Faster Time-to-Value: With its user-friendly interface and robust features, Databricks enables data engineers to build and deploy pipelines quickly, reducing the time-to-value for data-driven projects.
Features and Tools for Data Engineers
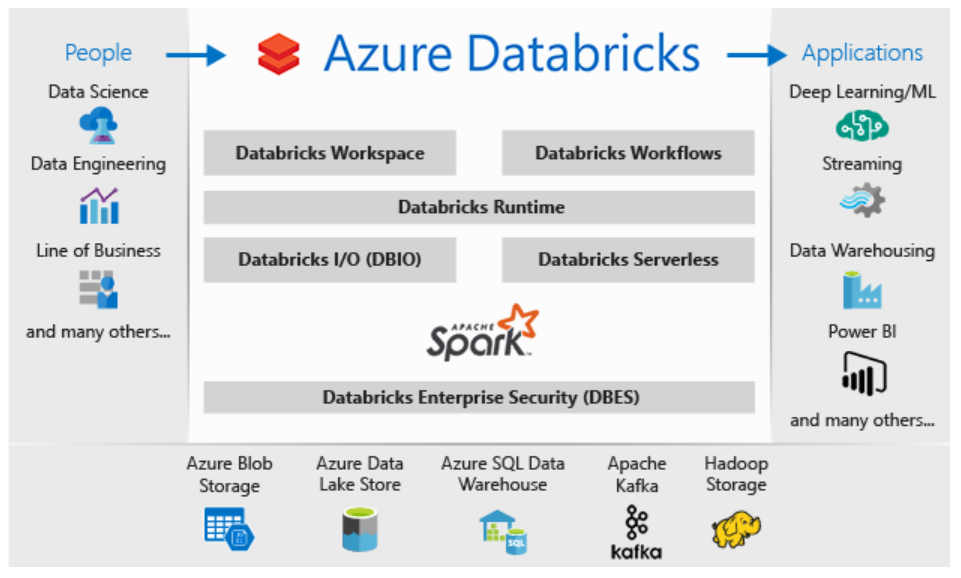
Databricks offers a variety of features and tools specifically designed for data engineers to enhance their productivity. These include:
Delta Lake
Delta Lake is an advanced storage layer that brings reliability to data lakes. It addresses common issues faced by data engineers, such as data corruption and inconsistency, by providing ACID (Atomic, Consistent, Isolated, Durable) transactions. With Delta Lake, data engineers can ensure data integrity and streamline their data pipelines by employing features like:
- ACID Transactions: Delta Lake provides ACID transactions, which make sure that data modifications are reliable and consistent, even in the case of concurrent updates.
- Schema Enforcement and Evolution: This feature ensures that the data is always written in a consistent format. Additionally, it allows for schema changes over time, accommodating evolving business needs without causing disruptions.
- Time Travel: Data engineers can easily access and query previous versions of the data, enabling quick rollback and effortless auditing of historical changes.
- Scalable Metadata Handling: Efficiently manages metadata so that even as the data grows, performance remains high, enabling fast data retrieval and operations.
Collaborative Notebooks
Databricks features interactive, collaborative notebooks that enable data engineers to write, execute, and document code in a unified environment. These notebooks support multiple languages including Python, R, Scala, and SQL, making it easy to switch contexts without switching tools. Key benefits of using collaborative notebooks include:
- Real-time Collaboration: Multiple engineers can work together in real time, simultaneously editing and running code, thereby enhancing productivity and teamwork.
- Integrated Documentation: Engineers can document their code directly within the notebook, ensuring that insights and methodologies are captured alongside the code.
- Visualization Tools: Built-in visualization tools allow for immediate data exploration and presentation, making it easier to understand and communicate insights.
Data Pipelines
Databricks streamlines the creation and management of data pipelines, providing tools that simplify complex processes. Through features like job scheduling, error handling, and monitoring, data engineers can build resilient and efficient pipelines. Key points include:
- Job Scheduling: Automate the execution of data pipelines to ensure that data processing tasks are performed at the right time without human intervention.
- Error Handling: Robust error handling mechanisms help to catch and manage errors, ensuring the smooth execution of pipelines and minimizing downtime.
- Monitoring and Logging: Built-in monitoring and logging tools provide detailed insights into pipeline performance and health, enabling data engineers to quickly identify and address issues.
Best Practices for Using Databricks

To maximize the benefits of Databricks and ensure smooth operation, data engineers should follow these best practices:
Optimize Cluster Configuration:
Optimize the cluster configuration by selecting the appropriate instance types and sizes based on workload requirements. Additionally, enabling auto-scaling and fine-tuning resource allocation can help achieve the perfect balance between performance and cost-efficiency.
Leverage Delta Lake Features:
Take full advantage of Delta Lake’s features such as ACID transactions, schema enforcement, and time travel capabilities. These features not only ensure data consistency and integrity but also make it easier to manage evolving data requirements without downtime.
Implement Version Control:
Use version control systems like Git to manage and track changes to notebooks, scripts, and configurations. This practice enhances collaboration, makes it easier to revert to previous versions, and ensures a comprehensive audit trail for all modifications.
Monitor and Optimize Performance:
Regular monitoring of job performance and resource utilization can provide insights into potential bottlenecks or inefficiencies. Use the monitoring tools provided by Databricks to analyze performance metrics, troubleshoot issues, and apply necessary optimizations.
Automate Testing and Deployment:
Implement automated testing to catch errors early in development and automate deployment processes to streamline the transition from development to production. Continuous integration and continuous deployment (CI/CD) pipelines can significantly improve the reliability and speed of data engineering workflows.
Secure Your Environment:
Ensure that data and processes within Databricks are secure by managing access controls, encrypting data at rest and in transit, and following best practices for securing clusters and notebooks. Regularly review and update security policies to meet evolving compliance and security requirements.
By adhering to these best practices, data engineers can fully harness the capabilities of Databricks, leading to more efficient, reliable, and scalable data workflows.
Real-World Applications of Databricks

Databricks can be implemented in a myriad of real-world scenarios to drive insights and innovation. Here are a few key applications:
Retail Analytics:
Retailers can leverage Databricks to analyze massive amounts of sales, inventory, and customer data. By integrating various data sources, businesses can generate actionable insights to optimize inventory management, personalize marketing campaigns, and enhance customer experiences through predictive analytics.
Financial Services:
In the financial sector, Databricks can be used to detect fraudulent activities by analyzing transaction patterns in real time, ensuring regulatory compliance, and performing risk assessments. By automating data pipelines and applying advanced machine learning algorithms, financial institutions can streamline operations and improve decision-making processes.
Healthcare and Life Sciences:
Databricks supports the healthcare and life sciences industries through applications such as genomics research, drug discovery, and patient data analytics. By processing large-scale genomic data, researchers can identify patterns and correlations that may lead to breakthroughs in treatments. Additionally, healthcare providers can use patient data to predict diseases, personalize treatment plans, and improve overall patient outcomes.
Manufacturing:
Manufacturers can optimize their supply chain and production processes by using Databricks for predictive maintenance and real-time monitoring. By analyzing sensor data from machinery and equipment, manufacturers can predict failures before they occur and schedule timely maintenance, reducing downtime and increasing operational efficiency.
Telecommunications:
Telecommunication companies can utilize Databricks to analyze call data records and network usage patterns, enhancing customer experience through improved network performance and targeted service offerings. Additionally, predictive analytics can be applied to forecast demand, manage resources, and design more effective marketing strategies.
Energy and Utilities:
Energy and utility companies can manage and analyze data from smart meters, grid sensors, and renewable energy sources using Databricks. By performing real-time data analysis, these companies can optimize energy distribution, predict equipment failures, and enhance grid reliability. Advanced analytics also enable better demand forecasting and energy efficiency initiatives.
By implementing Databricks in these diverse sectors, organizations can unlock the power of big data and advanced analytics, driving innovation and achieving competitive advantages in their respective fields.
Comparison of Databricks with Other Platforms
When evaluating data analytics platforms, it’s essential to compare Databricks with other leading solutions to understand where it excels and where it might fall short. Below are comparisons of Databricks with some other prominent platforms:
Databricks vs. Apache Spark:
While Databricks was founded by the creators of Apache Spark, it extends the capabilities of Spark with a managed, scalable platform for big data analytics. Databricks offers additional features such as Delta Lake, integrated machine learning tools, and a collaborative workspace with notebooks. Conversely, Apache Spark requires more setup and management effort but may be preferable for organizations seeking more control.
Databricks vs. Hadoop:
Hadoop, an older technology, handles large-scale data processing and storage through its Hadoop Distributed File System (HDFS) and MapReduce. Databricks, leveraging Spark, typically offers faster processing times due to its in-memory computing. Additionally, the user-friendly interface, built-in optimization techniques, and seamless integration with cloud services make Databricks a more agile solution compared to the relatively complex and slower Hadoop ecosystem.
Databricks vs. Snowflake:
Snowflake is a data warehouse solution optimized for cloud storage and analytics. It simplifies data management and offers high performance for SQL-based queries. In contrast, Databricks is more versatile, supporting not only SQL but also Python, R, and Scala, and it excels in machine learning and AI applications. While both platforms provide robust scalability and performance, the choice depends on whether the use case demands extensive machine learning capabilities (favoring Databricks) or a more traditional data warehousing approach (favoring Snowflake).
Databricks vs. Redshift:
Amazon Redshift is a managed data warehouse service in the AWS ecosystem, known for its strong SQL-based analytics capabilities. Databricks, however, shines in handling multi-language analytics, advanced machine learning, and real-time data processing. Organizations heavily invested in AWS might gravitate towards Redshift for ease of integration, while those requiring more extensive data engineering and machine learning capabilities might prefer Databricks.
Databricks vs. Google BigQuery:
Google BigQuery offers a serverless, highly scalable, and cost-effective multi-cloud data warehouse. It’s optimized for real-time analytics and integrates well with other Google Cloud services. While BigQuery excels in handling queries on massive datasets with minimal configuration, Databricks provides a more comprehensive toolset for data engineering, including support for complex machine learning workflows and a collaborative environment for data teams.
Conclusion
In conclusion, the decision to select a data analytics platform hinges on the specific needs and goals of the organization. Databricks, with its comprehensive features and robust support for machine learning and data engineering, stands out as a versatile solution for addressing complex data challenges. However, platforms like Apache Spark, Hadoop, Snowflake, Redshift, and Google BigQuery each have their own unique strengths, making them suitable for different scenarios. Evaluating these platforms based on factors such as scalability, ease of use, processing speed, and integration capabilities will ensure that businesses can leverage the right tools to drive innovation and achieve their strategic objectives.